Labeled Pedestrian in the Wild
General Information
The dataset is collected in three different crowed scenes. In the first scene there are three cameras placed, four cameras in the other two scenes. During collection, the cameras with the same parameters set were placed at the two junctions of the street. Labeled Pedestrian in the Wild consists of 2,731 different pedestrians and we make sure that each annotated identity is captured by at least two cameras, so that cross-camera search can be performed. A total of 7,694 image sequences are generated with an average of 77 frames per sequence.
The dataset has the following featured properties.
First, the dataset not only has the large scale but also it is clean by manually deleting the images detected error or tracking error.
Second, the bounding boxed is generated by pedestrian detector and misalignment is common among the detected images which fit the real situation.
Third, the dataset is collected in crowed scenes and there are more occlusion. It is more challenging in the following aspects: the age of characters varies from childhood to adulthood; the postures of human are diverse, including running and cycling;
The number of the folder indicates the identity of a person but it is not continuous. The same number in the different views of the same scene means same person. The detail about the dataset is in the following part.
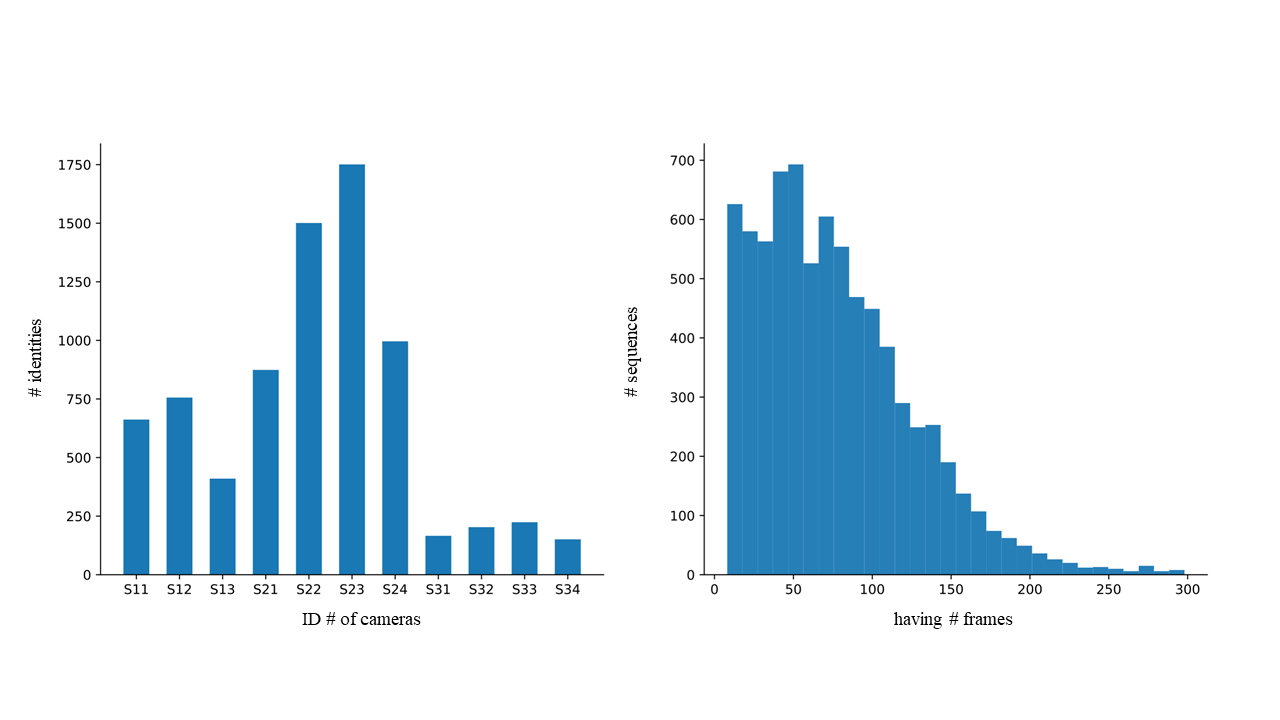
First column: the distribution of the number of identities in the cameras. The si cj means the identities captured by j-th camera in the i-th scene.
Second column: the distribution of the number of frames in the tracklets.
The specific information of the data set is shown in the following table.
| Scene1 | Scene2 | Scene3 | |||
|---|---|---|---|---|---|
| Identities | Identities | Identities | |||
| View1 | 662 | View1 | 874 | View1 | 166 |
| View2* | 756 | View2 | 1501 | View2 | 203 |
| View3 | 410 | View3* | 1751 | View3* | 224 |
| N/A | N/A | View4 | 996 | View4 | 151 |
The * means that the persons in this view are captured by at least one other camera in the same scene.
Here are some samples from LPW.

Evaluation Protocol
Labeled Pedestrian in the Wild is evenly divided into train and test sets, containing in 1,975 and 756 identities, respectively. The persons in the second scene and third scene will be used for training and the first scene will be used for testing. In the testing set, the persons in the second view will be the probe and people in the other two views will be the gallery. There are 756 probes and 1,072 galleries and for the same probe there will be multiple galleries. The dataset is large, so we fix the train/test partitioning instead of repeating random partitioning for 10 times.
We use the CMC curve (Cumulative Matching Characteristic, representing the expectation of the true match being found within the first n ranks) as the evaluation metric. Given a query image sequence, all gallery identities are assigned a similarity score and the galleries will be ranked according to their similarity to the query. All the persons in probe set appeared in the gallery set.
| Training set | Identities | Probe set | Identities | Gallery Set | Identities |
|---|---|---|---|---|---|
| Scene2 | 1751 | Scene1_view2 | 756 | Scene1_view1+view3 | 1072 |
| Scene3 | 224 | N/A | N/A | N/A | N/A |
Result of baseline
| Rank | 1 | 5 | 10 | 20 |
|---|---|---|---|---|
| GoogLeNet[1]+Batch normalization[2] | 41.5 | 66.7 | 77.2 | 86.2 |
| RQEN | 57.1 | 81.3 | 86.9 | 91.5 |
Downloads
You can download the LPW dataset (cleaned version) below.
Related Publications
If you use this dataset in your research, please kindly cite our work as,
@inproceedings{song_2018_rqen,
Author = {Guanglu Song, Biao Leng, Yu Liu, Congrui Hetang, Shaofan Cai},
Title={Region-based Quality Estimation Network for Large-Scale Person Re-identification},
Booktitle={AAAI},
Year = {2018}
}
Reference
[1] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Goingdeeperwithconvolutions. InCVPR,2015.
[2] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
